

Easy遺伝解析(エクソーム)
あなたの全エクソン領域を、手軽にデータ化。必要があれば解析します。
頬粘膜スワブによる「エクソーム解析 & FASTQデータ提供」サービス
当サービスは、お客様のDNAのうち、タンパク質をコードする重要な領域である「エクソーム(全エクソン領域)」を網羅的に次世代シーケンサー(NGS)で解析し、生の配列データであるFASTQ形式でご提供するサービスです。
医療機関での採血は不要。ご自宅で完結する痛みのない採取方法で、ご自身の遺伝子データを取得していただけます。
🧬 当サービスの特徴
- 痛みのない手軽なサンプル採取 専用のスワブ(綿棒)で頬の内側(頬粘膜)をこするだけ。採血の必要がなく、ご自宅で簡単かつ安全にDNAサンプルを採取できます。
- 高品質な生データ(FASTQ)の提供 バイオインフォマティクス解析のベースとなる、シーケンス生データ(FASTQファイル)を直接ご提供します。ご自身の研究、独自のパイプラインでの解析、将来の技術発展に備えたデータの自己管理に最適です。
- スムーズなオンライン納品 解析完了後、セキュアな専用サーバーよりデータを直接ダウンロードしていただけます。物理的なメディアのやり取りによるタイムロスや紛失のリスクがありません。
- 納期(TAT: 約2ヶ月) サンプルが当施設に到着してから、**約2ヶ月(ターンアラウンドタイム)**でデータの準備が完了します。
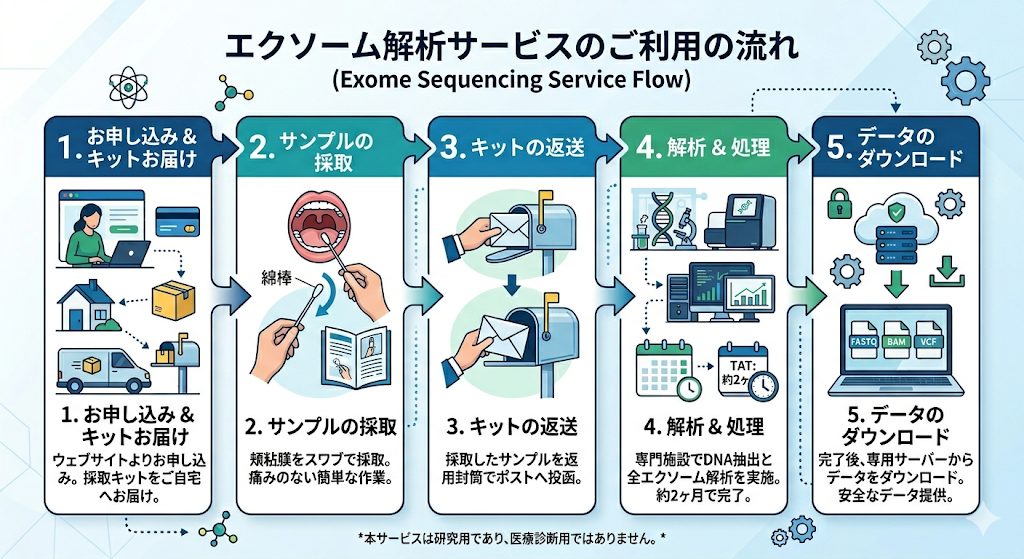
🔄 サービスのご利用の流れ
STEP 1:お申し込み・キットの受け取り 当ウェブサイトよりご注文ください。数日以内に、ご指定の住所へ「DNA採取キット(スワブ)」をお届けいたします。
STEP 2:サンプルの採取 キットに同梱されている説明書に従い、頬粘膜をスワブで採取してください。所要時間はほんの数分です。
STEP 3:サンプルのご返送 採取済みのサンプルを返信用封筒に入れ、ポストへ投函してください。
STEP 4:エクソーム解析(約1ヶ月) サンプル到着後、専門施設にてDNAの抽出および次世代シーケンサーによる全エクソーム解析を行います。
STEP 5:データのダウンロード 解析が完了しましたら、ご登録のメールアドレスにダウンロードリンクとアクセス手順をご案内します。お好きなタイミングでFASTQデータをダウンロードしていただけます。ただし保管期間は1ヶ月です。1ヶ月を超えた時点でデータは削除されます。
⚠️ ご利用にあたっての重要な注意事項
- 本サービスは「データ(FASTQ形式)」の提供のみを目的としています。
- 疾患リスクの判定、祖先ルーツの解析、バリアントの注釈付けなどの「解析レポート」は付属しておりません。
- ご提供するFASTQデータを活用・解釈するには、バイオインフォマティクスの専門知識や専用の解析環境が必要となります。
ご不明な点がございましたら、お気軽に[お問い合わせフォーム/リンク]よりご連絡ください。
FASTQ(ファストキュー)データとは、次世代シーケンサー(NGS)というDNA解析装置から直接出力される、**「生のDNA配列」と「読み取りの品質(正確さ)」**をセットで記録したテキストデータのことです。
バイオインフォマティクス(生命情報科学)の世界では、遺伝子解析の最もベースとなる「大元の生データ」として標準的に扱われています。
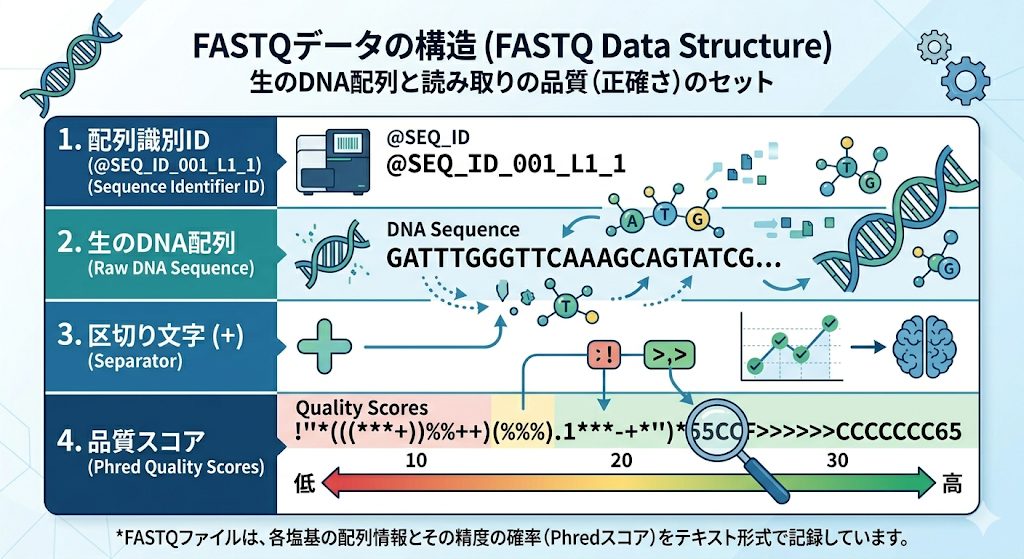
🧬 FASTQデータの構造(4行1セット)
FASTQファイルの中身はテキスト(文字)の羅列です。1つのDNAの断片(リードと呼びます)のデータが、必ず以下の4行1セットで構成されています。
Plaintext
@SEQ_ID_001
GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT
+
!''*((((***+))%%%++)(%%%%).1***-+*''))**55CCF>>>>>>CCCCCCC65
- 1行目(ID):
@(アットマーク)から始まり、シーケンサーの機器番号や配列の識別IDなどが書かれています。 - 2行目(塩基配列): 機械が実際に読み取ったDNAの配列です。A(アデニン)、T(チミン)、C(シトシン)、G(グアニン)の4文字(不明な場合はN)で並んでいます。
- 3行目(区切り):
+(プラス)記号が入り、2行目と4行目を区切ります。 - 4行目(品質スコア): 2行目で読み取った**それぞれの塩基(A, T, C, G)に対する「自信の度合い(Phredスコア)」**を表しています。
📊 なぜ「品質スコア」が暗号のような記号なのか?
4行目の !''*((((***+... という記号の羅列は、文字化けではありません。
次世代シーケンサーは数億個のDNA断片を高速で読み取りますが、ごく稀に読み取りエラー(AをTと読み違えるなど)を起こします。そのため、「このAは99.9%の確率で正しい」「このGは少し自信がない」という品質(確度)を数字で記録する必要があります。
しかし、数字(例:99.9%や、スコア30など)をそのまま書き込むとデータ容量が膨大になってしまうため、コンピューター上で1文字分の容量で済む**「ASCII(アスキー)文字」と呼ばれる記号やアルファベットに変換して記録**しています。
🗺️ 遺伝子解析の流れにおけるFASTQの立ち位置
遺伝子解析は、一般的に以下のようなステップで進みます。
- DNA採取・抽出(スワブなどで採取)
- シーケンス解析(機械でDNAを読み取る)
- 【FASTQファイルの生成】 ◀︎ 今回提供するデータはココ
- マッピング(BAM/SAMファイル)(読んだ断片を、人間の標準ゲノムの「どこに当てはまるか」パズルのようにマッピングする)
- 変異コール(VCFファイル)(標準ゲノムと違う部分=変異をリストアップする)
お客様にFASTQデータを提供するということは、**「誰の手も加わっていない、機械が読み取ったままの一番ピュアな状態のデータをお渡しする」**ということを意味します。そのため、研究者などは自身の目的に合わせた専用のソフトウェア(パイプライン)を使って、このFASTQデータから自由に情報を引き出すことができます。
FASTQデータをどう活用する。
💻 FASTQデータを情報に変換するステップ(パイプライン)
- 品質管理とクリーニング(QC: Quality Control) FASTQデータ(4行目の品質スコア)を参照し、「読み取り精度が低い部分」や「解析に不要な配列(アダプター配列など)」をソフトウェアで切り落とし、綺麗なデータに整えます。
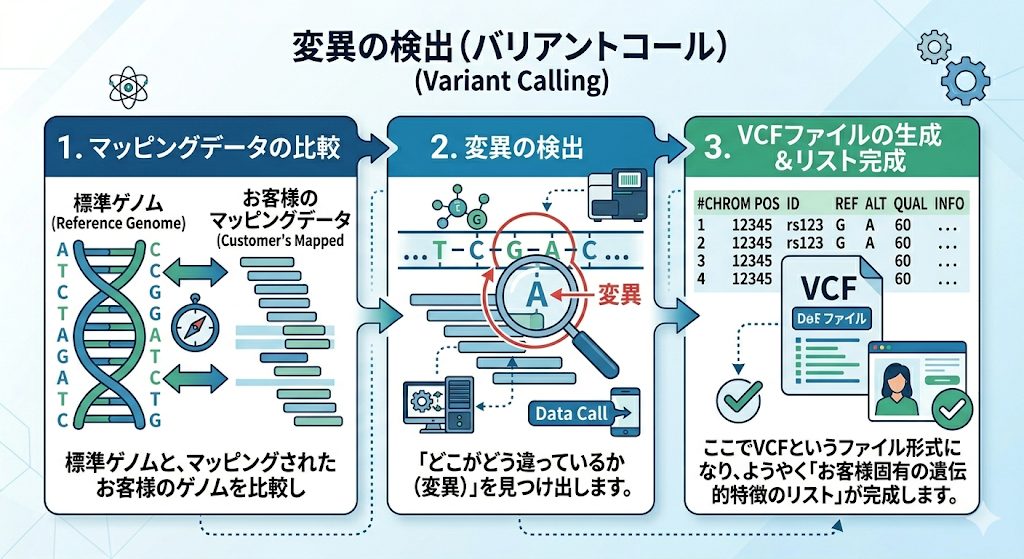
- マッピング(アライメント) バラバラのDNA断片(パズルのピース)を、人類の「標準ゲノム配列(完成図)」に照らし合わせて、ゲノム上のどの部分の配列なのかをコンピューター上で貼り付けていきます。ここでBAMやSAMと呼ばれるファイル形式に変換されます。
- 変異の検出(バリアントコール) 標準ゲノムと、マッピングされたお客様のゲノムを比較し、「どこがどう違っているか(変異)」を見つけ出します。ここでVCFというファイル形式になり、ようやく「お客様固有の遺伝的特徴のリスト」が完成します。
- 意味づけ(アノテーション) 見つかった変異が、「どのような体質に関連しているのか」「特定のタンパク質にどう影響するのか」を、世界中の学術的な遺伝子データベースと照らし合わせて解釈します。
👤 実際にFASTQデータを受け取った人はどう使うのか?
当サービスでFASTQデータを受け取ったお客様は、主に以下のような目的で活用されることが想定されます。
- 研究・開発目的(プロ・研究者向け) 大学の研究者や企業のエンジニアが、自作の解析アルゴリズムを検証したり、既存のパイプラインに流し込んで独自の遺伝子研究を行うための「ピュアな基礎データ」として利用します。
- 個人でのデータ解析・サードパーティサービスの利用(IT技術者・DIYバイオ向け) プログラミング知識がある方やバイオインフォマティクスを学ぶ学生などは、クラウド環境やハイスペックPCを用いてオープンソースのツール(BWA、GATKなど)を動かし、ご自身でVCFファイルへの変換を行います。その後、外部の遺伝子解釈サービスにデータを読み込ませて、自分の体質などを独自に調べるケースがあります。
- 将来の技術発展に向けた「生データ資産の保管」 遺伝子を解釈する技術やデータベースは日々進化しています。数年後には、今はわからなかった新しい発見がご自身のデータから引き出せるようになるかもしれません。解釈済みのPDFレポートだけでなく、「一生変わらない自分自身の生データ(FASTQ)」を手元に保有しておくことで、将来登場する未知の解析サービスにいつでも対応できる状態にしておく、という究極のデータ所有の形です。
このように、FASTQデータは「可能性の塊」ですが、直接的な恩恵を得るにはデータの加工と解釈のステップが必要になります。
料金プラン(価格表)
お客様のご要望に合わせて、生データの提供から高度な解析まで、段階的なプランをご用意しております。
※表示価格はすべて税抜き価格です。
1. 基本サービス(データ取得)
まずは自分の生データを保有したい方、ご自身で解析環境をお持ちの方向けの基本プランです。
| サービス名 | 内容 | 価格(税抜) |
| エクソーム解析 | 頬粘膜スワブによるDNA採取・次世代シーケンス解析、FASTQ形式でのデータ納品 | 9,800円 |
2. データ加工オプション
FASTQデータを、一般的な解析ソフトで扱いやすい形式に変換するサービスです。
| サービス名 | 内容 | 価格(税抜) |
| マッピング処理 | FASTQからBAM/SAM形式への変換(標準ゲノムへの紐付け) | + 5,000円 |
| バリアントコール | FASTQからVCF形式への変換(変異箇所の特定) | + 10,000円 |
3. アノテーション(変異の解釈・意味付け)
検出された変異が、どのような疾患や体質に関連しているかを調査・レポートする高度な解析オプションです。
| サービス名 | 内容 | 価格(税抜) |
| 初期費用 | VCF形式からデータベース照合および解析 | 20,000円 |
| 遺伝子アノテーション | 指定された遺伝子(1遺伝子につき)の変異解釈 | 3,000円 / 1遺伝子 |
遺伝子カウンセリンング 1時間3万円(税抜)
💡 お見積り例
- 「まずは生のデータだけ手元に持っておきたい」場合
- エクソーム解析(FASTQ):9,800円
- 「変異リスト(VCF)まで作成してほしい」場合
- エクソーム解析+VCF変換:19,800円
- 「特定の遺伝子(例:BRCA1)にどんな変異があるか知りたい」場合
- エクソーム解析+VCF変換+アノテーション初期費用+1遺伝子指定:42,800円
使用する解析データベース
🌍 集団アレル頻度データベース (Population Frequencies)
健常者や一般集団において、その変異がどのくらいの頻度で存在するかを確認するためのデータベースです。
- gnomAD (Exomes, Genomes, Structural Variants など)↳
- 1000 Genomes Project
- dbSNP
- ExAC (Exome Aggregation Consortium)↳
- TopMed
- Kaviar
🏥 疾患・臨床的意義データベース (Clinical & Pathogenicity)
変異と遺伝性疾患などの関連性、および過去の病的意義の分類をまとめたデータベースです。
- ClinVar (NCBIが運営する臨床的変異のデータベース)
- OMIM (Online Mendelian Inheritance in Man:遺伝性疾患と遺伝子のカタログ)
- dbNSFP (ヒト非同義変異のための統合データベース)
- LOVD (Leiden Open Variation Database)↳
- Orphanet (希少疾患のデータベース)
- HGMD (Human Gene Mutation Database) ※プロ版の利用には別途ライセンスが必要な場合があります。
🧬 がん関連・体細胞変異データベース (Oncology / Somatic)
がんゲノム解析(体細胞変異)の解釈や、ターゲット治療薬の検討に用いられます。
- COSMIC (Catalogue Of Somatic Mutations In Cancer)↳
- CIViC (Clinical Interpretation of Variants in Cancer)↳
- PMKB (Precision Medicine Knowledgebase)↳
- ICGC (International Cancer Genome Consortium)↳
- OncoKB ※別途ライセンス要件がある場合があります。
💻 In Silico 予測ツール・保存性スコア (In Silico Predictors)
アルゴリズムを用いて、その変異がタンパク質の機能やスプライシングに悪影響を与えるか(網羅的スコアや進化的な保存性)を予測します。
- 総合・ミスセンス予測: REVEL, CADD, SIFT, PolyPhen-2, MutationTaster, DANN, MetaLR
- スプライシング予測: SpliceAI, scSNV, MaxEntScan, SpliceVarDB
- 保存性スコア: PhyloP (100wayなど), PhastCons
💊 薬理ゲノミクス・薬剤相互作用 (Pharmacogenomics)
特定の遺伝子変異と、薬剤の効き目や副作用との関連を示します。
- PharmGKB (Pharmacogenomics Knowledgebase)↳
- CPIC (Clinical Pharmacogenetics Implementation Consortium)↳
- DGIdb (Drug-Gene Interaction Database)↳
📖 遺伝子・転写産物・構造アノテーション (Gene & Transcript)
遺伝子の正確な位置、転写産物(トランスクリプト)の定義、タンパク質の構造ドメインなどを特定します。
- Ensembl
- RefSeq (NCBI)↳
- UniProt (タンパク質機能・配列情報)
- Pfam (タンパク質ドメイン)
免責事項
1. 本サービスの目的と医療行為・診断の否定
- 当サービスは、お客様のDNA情報を生データ(FASTQ形式等)として抽出し提供すること、および指定のデータベースに基づいた学術的なアノテーション情報を提供することを目的としています。研究用、あるいは個人のデータ保管・自己探求を目的としたものであり、いかなる医療行為・医療診断にも該当しません。
- 当サービスが提供するデータおよびアノテーション結果は、疾患の診断、予防、治療方針の決定、または特定の医薬品の効果・副作用の判定に利用することはできません。健康状態にご不安がある場合は、必ず専門の医療機関または医師にご相談ください。
2. 解析技術と精度の限界
- 当サービスでは最先端の次世代シーケンサー(NGS)およびバイオインフォマティクス技術を用いて解析を行いますが、現在の科学技術の性質上、100%の網羅性および正確性を保証するものではありません。
- 全エクソン領域(エクソーム)を対象としますが、GC含量が極端に高い領域、リピート配列、構造異常(大きな欠失や重複など)によっては、十分な読み取り(カバレッジ)が得られない、または変異を検出できない場合があります。
3. サンプルの品質と解析の可否について
- お客様によるサンプルの採取状態(頬粘膜の採取量不足、飲食直後の採取による不純物の混入など)によっては、解析に十分なDNAが抽出できず、解析に失敗する場合がございます。
- 品質基準を満たさない場合、再採取(キットの再送付)をお願いすることがございます。その際、追加のキット費用や送料が発生する場合があります。また、複数回試みても解析困難と判断された場合は、サービスをキャンセルとさせていただくことがございます。
4. データの利用とお客様の責任
- 納品された生データ(FASTQ, BAM, VCF形式等)を利用したことによる、お客様または第三者のいかなる不利益、損害、心理的負担について、当社は一切の責任を負いません。
- お客様ご自身でサードパーティの解析ツールや外部サービスへ当データをアップロードし利用された場合、それに伴う個人情報の漏洩リスクや、誤った解析結果に基づくトラブルについて、当社は関与せず責任を負いかねます。
5. アノテーション(変異の解釈)に関する免責
- アノテーションオプションにて提供される情報は、解析時点における公的データベース(ClinVar, gnomAD等)や学術論文の情報を参照したものです。科学・医学の研究は日々進歩しており、特定の遺伝子変異に対する解釈や病的な意義(病的か、良性かなど)は、将来の新たな発見により変更される可能性があります。
- データベースの情報そのものの正確性について、当社が保証するものではありません。
6. サービスの一時中断・変更
- 自然災害、通信回線の障害、システムメンテナンス、シーケンサー等機器の突発的な故障など、当社のコントロールが及ばない事態が発生した場合、予告なくサンプルの解析遅延、サービスの停止または中断が生じる場合があります。これによってお客様に生じた損害について、当社は一切の責任を負いません。
詳しくは ヒロクリニック全国のクリニック一覧 をご覧ください。